網絡工程設計與安裝 現代實踐與優(yōu)化策略

網絡工程設計與安裝是構建可靠、高效網絡系統(tǒng)的核心環(huán)節(jié),它不僅涉及技術實現,還關系到企業(yè)的通信效率與安全。隨著信息技術的飛速發(fā)展,《網絡工程設計與安裝(第4版)》等專業(yè)教材為從業(yè)者提供了系統(tǒng)的知識框架。本文將基于網絡工程設計與安裝的關鍵原則,探討其實踐步驟和優(yōu)化策略。
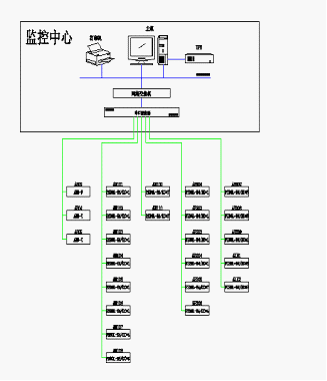
網絡工程設計始于需求分析。必須明確網絡的應用場景、用戶數量、帶寬需求以及安全要求。例如,企業(yè)網絡可能強調高可用性和可擴展性,而教育機構則更注重成本效益。通過調查和訪談,設計人員可以制定出合理的拓撲結構,如星型、環(huán)形或混合拓撲。在設計中,還需考慮協(xié)議選擇,如TCP/IP協(xié)議族,以及設備選型,如交換機、路由器和防火墻的配置。
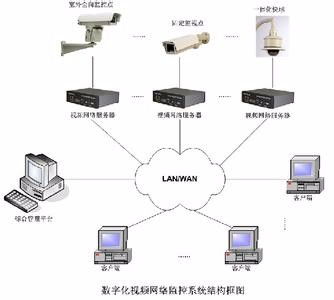
隨后,網絡安裝階段將設計藍圖轉化為現實。這包括物理安裝,如布線(光纖或雙絞線)、設備機柜的布置,以及邏輯配置,如IP地址分配、VLAN劃分和路由設置。安裝過程中,測試是必不可少的環(huán)節(jié),使用工具如ping、traceroute或專業(yè)網絡分析儀,以驗證連接的穩(wěn)定性和性能。同時,安全措施必須貫穿始終,例如部署防火墻規(guī)則、加密傳輸數據,并建立監(jiān)控系統(tǒng)以檢測異常。
在實施后,維護和優(yōu)化成為持續(xù)任務。網絡工程并非一勞永逸,定期更新固件、備份配置、監(jiān)控流量模式可以幫助預防故障。隨著物聯網和5G技術的普及,網絡設計需具備前瞻性,支持未來擴展。通過案例學習,如某企業(yè)升級到SD-WAN以提升分支機構的連接效率,我們可以看到創(chuàng)新技術如何提升網絡性能。
網絡工程設計與安裝是一個動態(tài)的、多階段的流程,它要求工程師結合理論知識與實際經驗。通過系統(tǒng)規(guī)劃、嚴格安裝和持續(xù)優(yōu)化,可以構建出健壯的網絡基礎設施,支持數字化時代的各種應用。參考《網絡工程設計與安裝(第4版)》等資源,從業(yè)者能不斷精進技能,應對日益復雜的網絡挑戰(zhàn)。
如若轉載,請注明出處:http://www.52100e.cn/product/17.html
更新時間:2026-06-15 02:46:55